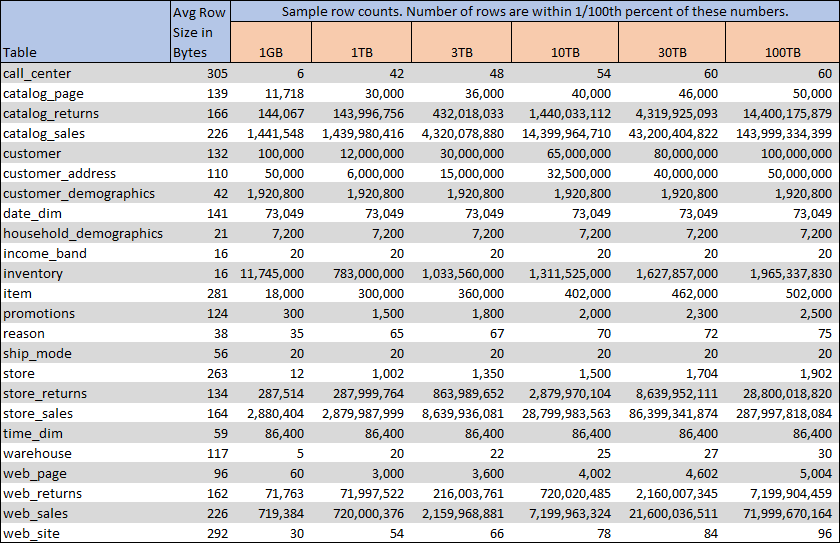
Update 2020-05-29: Generate Big Datasets with Databricks
I authored a post on the BlueGranite site on how to generate big datasets with Databricks. This is a more modern approach to generating the same TPC-DS benchmark datasets, and I recommend it over the HDInsight solution described below.
The TPC (Transaction Processing Performance Council) provides tools for generating the benchmarking data, but using them to generate big data is not trivial, and would take a very long time on modest hardware. Thankfully someone has written a nice utility that uses Hive and Python to run the generator on a Hadoop cluster. While Hadoop clusters are not easy to setup, using a Hadoop cloud service like Azure HDInsight is remarkably easy. With HDInsight, you can use a powerful cluster of machines to generate the data quickly, and when you’re done you can delete the cluster, leaving the data in place.

Before you Start
Since you’re paying for HDInsight while it’s running, you want to be prepared and work efficiently to minimize costs.
- Read through this post and the instructions in the tpcds-hdinsight repository, so that you’re familiar with the steps in advance.
- Decide where you want to store the data, and prepare the storage location (Blob Storage or Azure Data Lake). Make sure that it’s in a region where HDInsight is available.
- Decide if you also want to convert the data to ORC format, and if so, prepare the storage location.
It is assumed that the reader has some experience with the Azure Portal, SSH, and the Linux command line.
Create an HDInsight Cluster
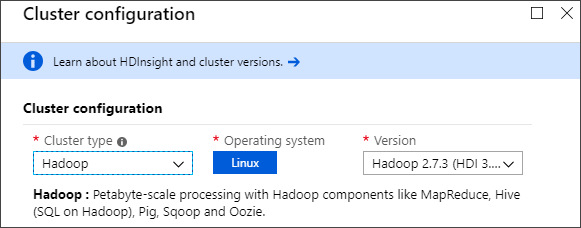
When selecting a storage option, decide where you’d like to keep the sample data long term, because the data will remain when the cluster is deleted. If you don’t know which one to choose, I’d suggest Azure Storage. Azure Storage pricing is low, and it’s easiest to configure with HDInsight in terms of permissions.
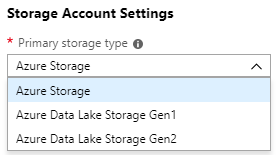
There are some other options for additional storage and metastores. Proceed with the defaults unless you’re familiar with these options.
Optional - Using Azure SQL Database as an external metastore is very useful if you know that you’ll want access to Hive or Oozie metadata in the future. For example, if you want to create an HDInsight cluster at a later date to query existing data with Hive, you could do so without having to recreate tables.
Tip - Creating an HDInsight cluster with multiple storage accounts is very useful if you want to move data from one storage account to another. The DistCp (Distributed Copy) tool in Hadoop can copy large volumes of data in parallel, and preserve permissions in the process.
If you’re fine with the default cluster size, proceed with creating the cluster. I used the default cluster (4 x D4 v2 worker nodes) when generating a 1TB dataset, and it took 2 hours and 22 minutes.
Generating the Data with Hive
Once the cluster has been created, you can connect to it with SSH and begin with the instructions in the tpcds-hdinsight repository. If writing the data to Azure Blob Storage, the command to generate the data will look something like this:
/usr/bin/hive -i settings.hql -f TPCDSDataGen.hql -hiveconf SCALE=1000 -hiveconf PARTS=1000 -hiveconf LOCATION='wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>' -hiveconf TPCHBIN=resources
While the job is running, you should see output similar to the screenshot below. In this screenshot the data is being written to Azure Data Lake Store Gen 1.
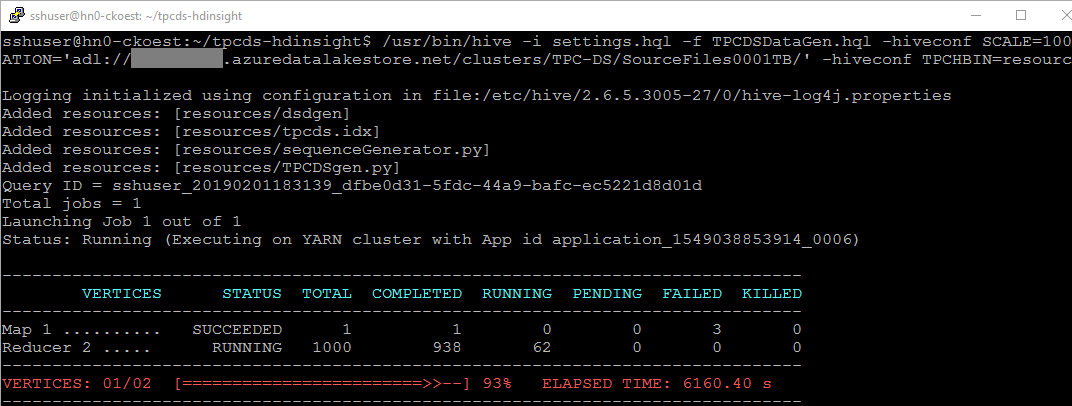
When the job is done you can check the disk usage with the Hadoop File System (FS) shell du command

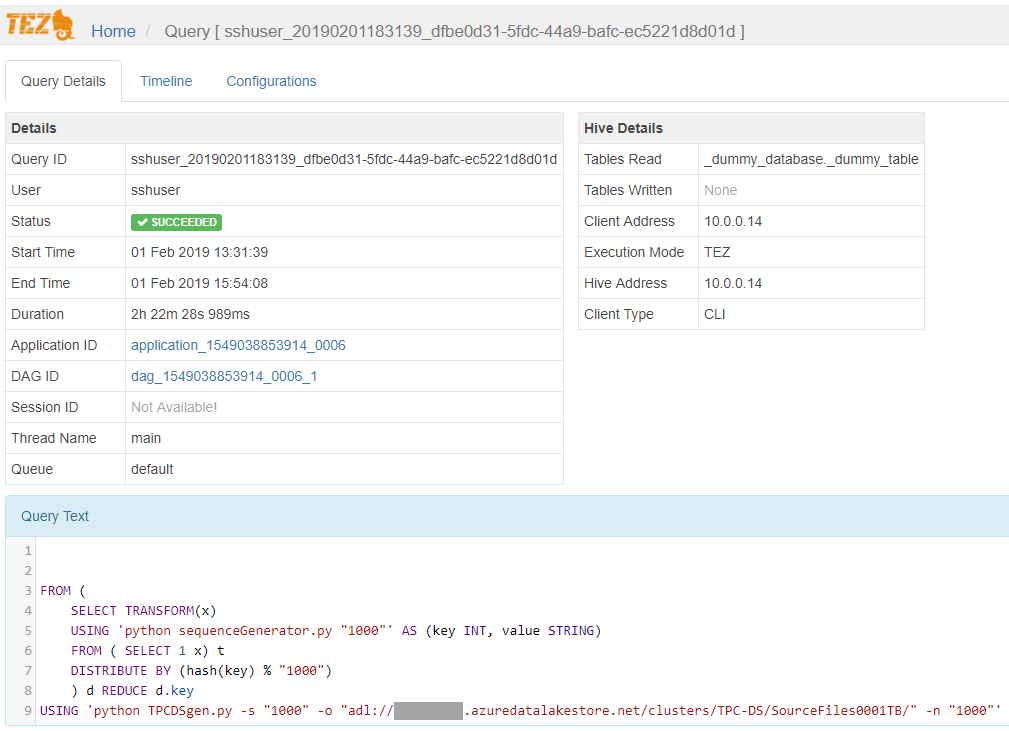
You can also check the job duration and other details in Ambari, which is linked from the HDInsight resource in the Azure Portal.
Optional Conversion to ORC
The tpcds-hdinsight repository also contains instructions and DDL code for converting the data to ORC format. ORC is a popular file format that provides significant benefits in terms of compression and query performance. If you’re not sure if you need this, you can skip this step.